
psadmin.conf: Elasticsearch Clusters on Kubernetes
In this session from psadmin.conf 2018, JR Bing gives an introduction to Kubernetes and then dives into why he is using it to run an… Read More »psadmin.conf: Elasticsearch Clusters on Kubernetes
In this session from psadmin.conf 2018, JR Bing gives an introduction to Kubernetes and then dives into why he is using it to run an… Read More »psadmin.conf: Elasticsearch Clusters on Kubernetes
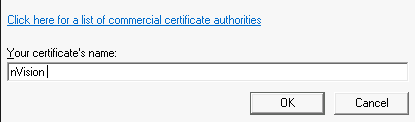
Signing nVision Macros If you have to support nVision reports, you’ve probably had to deal with getting nVision configured on developer workstations. To develop nVision… Read More »Signing nVision Macros
Sign up for an Oracle Cloud Trial Account Oracle Cloud Trial Sasank Vemana – PeopleSoft on the Cloud Create SSH key ssh-keygen -f ~/.ssh/cmtrial cat… Read More »Cloud Manager Installation
In this session from psadmin.conf 2018, David Vandiver demonstrates his Process Monitor 2.0 bolt-on. David redesigned the Process Monitor from scratch and added many improvements.… Read More »psadmin.conf: Process Monitor 2.0

One complaint I have about using PeopleSoft Images is that logging in and opening pages is very slow. Behind the scenes, the application server is… Read More »Speed up PeopleSoft Images
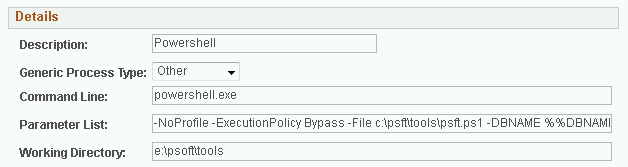
Process Scheduler and Powershell Scripts The PeopleSoft Process Scheduler supports many different types of tools to run, but one thing it lacks is support to… Read More »Process Scheduler and Powershell
A few weeks ago we presented an “Introduction to Deployment Packages” session to a user group. We re-recorded the session so you can view it… Read More »Introduction to Deployment Packages Talk
The next video from psadmin.conf 2018 is available! Kyle Benson and Dan Iverson look at Terraform, a cloud provisioning tool, and show how psadmin.io uses… Read More »psadmin.conf: Terraforming PeopleSoft
The next video from psadmin.conf 2018 is available! Nate Werner focuses on sing change management (Git/GitHub) for your collection of admin and monitoring scripts and… Read More »psadmin.conf: Automation Challenges for Administrators
This week Kyle and I presented at OpenWorld 2018. Our session talked about how to take advantage of Deployment Packages, using ACM to simplify database… Read More »Advanced PeopleSoft Administration – OpenWorld 2018