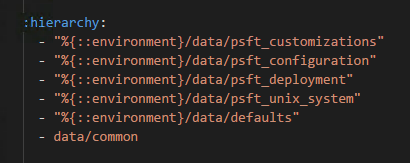
Using Puppet Environments with the DPK
Since the Deployment Packages were released with PeopleTools 8.55, one of my criticisms has been that the DPK is a bit of a sledgehammer. If… Read More »Using Puppet Environments with the DPK
Since the Deployment Packages were released with PeopleTools 8.55, one of my criticisms has been that the DPK is a bit of a sledgehammer. If… Read More »Using Puppet Environments with the DPK

This week on the podcast, we share Eric Bolinger’s DPK module for WebLogic, Graham’s 5 Things about PeopleSoft Images, more Fluid Ideas, and dive into… Read More »#95 – You are here
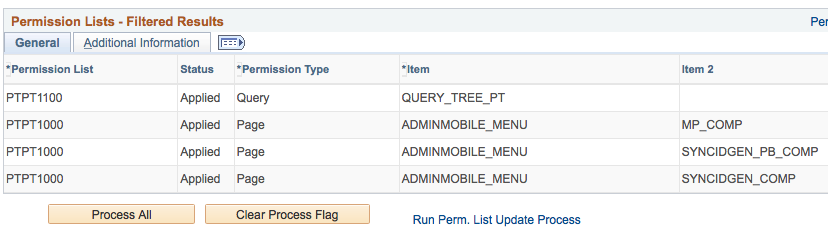
In recent PeopleSoft Image updates, a new tool for implementing security changes was introduced. The Security Deployment tool simplifies the application of new security changes… Read More »Using Security Deployment with Custom Security
This week, Dan and Kyle talk about linting and the tnsnames.ora file, managing a Portal reimplementation proejct and follow-up on the TimesTen database. Then Kyle… Read More »#94 – LOCAL_NODE
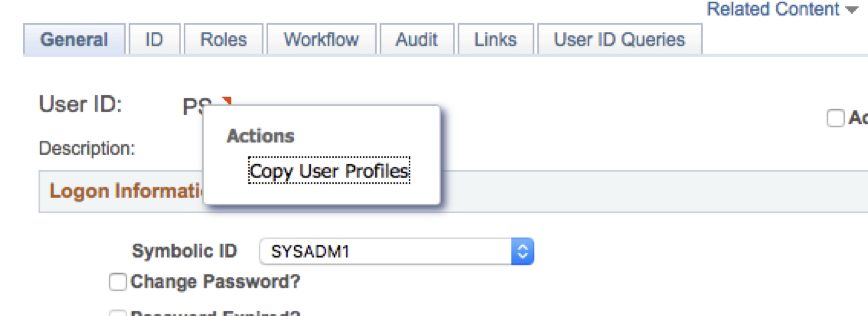
The Related Content Framework has been part of PeopleTools for a while (8.50 I think), but recently I have rediscovered how great this framework is.… Read More »Improving the User Profile Component with Related Content
This week on the podcast, Kyle recaps the Phire User Group meeting, his PTF talk, and shares a nice tip on integrating Usage Monitor with… Read More »#93 – Forced Adoption
The way PeopleSoft delivers Puppet and the Hiera backend, is that everything you define in psft_customizations.yaml overrides configuration defined elsewhere. This is a useful setup… Read More »Convert the DPK to use Hiera Hash Merging
This week on the podcast, Dan dives into some advanced Puppet configuration to use with the DPK. Dan and Kyle discuss Hiera hash merging, using… Read More »#92 – Advanced Puppet with the DPK
The PeopleSoft Cloud Architecture is built on two technologies: Deployment Packages (DPK) and Automated Configuration Management (ACM). On this site, we’ve talked about Deployment Packages… Read More »Using Automated Configuration Management with the DPK